NH-LoRA
Preface
Tl;dr :
We proposed new LoRA architecture called NH-LoRA as part of PEFT on Continual Learning, spesifically on image classification. We also show it's performance on Continual Learning task with final average accuracy and forgetting.
Hello ! So... this project is a part of collaboration between me (Hartmann) and Syauqi. Anyway, this new architecture was inspired by neuromorphic computing [3], DEN [5], and CL-LoRA method [2]. The problem domain itself, Class-Incremental Learning, was relatively new and rarely discussed (at least at the time I wrote this). But, we believe it could be very useful for existing models, especially when they need to be maintained over time and able to learn new knowledge, without forget the old one. That, is what we want to address.
Oh, btw, this was make as KCVanguard Final Project, part of KCV Lab Recruitment. Maybe, we'll make the Indonesian version of this (and I'll put it here). Because this is a new architecture, there will be really, really lot of equation here. We'll try to explain them in a comprehensive, structured, and (hopefully) easy-to-understand way.
Links
For those who just wonder about the architecture, u can skip to here
Problem Statement
Image Classification
Image Classification is simply a task to give a label to an image. Every image classification model have this common idea :
- Input the image
- Passes it through a series of layers
- Decides the most likely categories
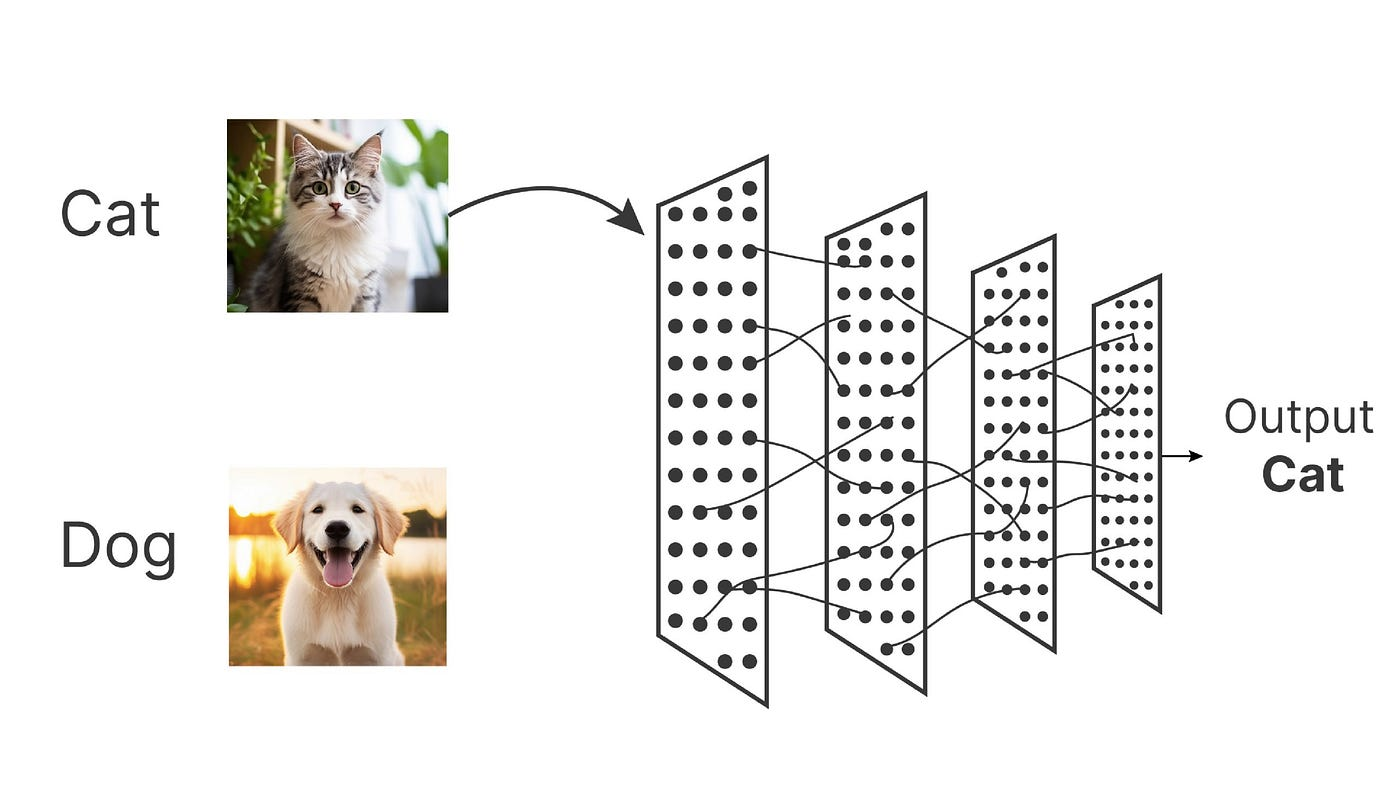
(Incremental) Image Classification
In image classification, a model is trained on a fixed set of classes, so it only learns to recognize classes within that domain.
hmmm.... What if we want to add a new class later ?
Well, we can fine-tune or retrain the model. Let's say I chose to fine-tune because I don't have time to retraining. So the model learn the new concept well, but somehow, maybe it lose some ability to recognize the old ones at the same time. This is known as forgetting, common problems on fine-tuning.
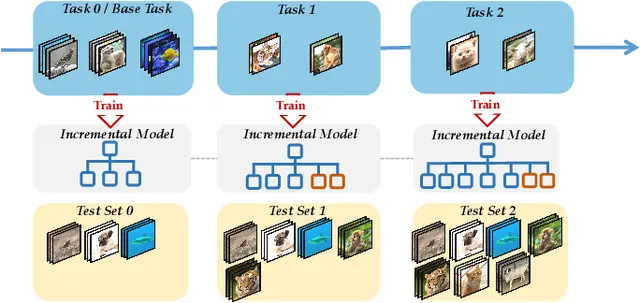
So, incremental learning can be viewed as a special task in fine-tune domain [1]. We add new classes over time while try to preserve performance on previously learned classes (Btw, we use the term incremental here, but it's similar with continual learning)
Formally, we can think of the learning process as a sequence of tasks
After training on task
In short, this diagram should helps the intuition :
To deal with incremental image classification, we use vision transformer model. There are more model tho, but we use this because it's the same model that CL-LoRA use, so the benchmark can be done fairly.
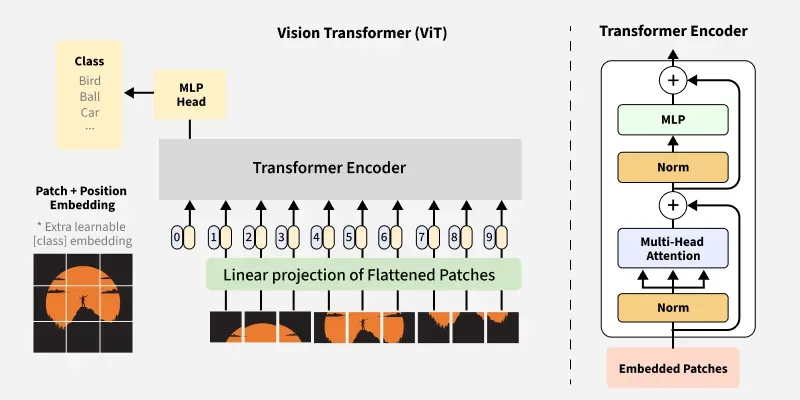
Vision Transformer (ViT)
Vision Transformers (ViT) is a Transformer but for images, works by treating image patches as tokens.
Transformers? Thought that was for NLP, iirc? ... Yep, but the idea actually can be used for images as well. I think better we explained some concept here to make sure we are on the same page ....
Transformer
Transformers are models that process a sequence by letting each element compare itself with the others, instead of reading everything in a fixed (left-to-right) order [6]. Transformer is identical with attention (imo, since these two terms are often mentioned together).
... attention, like how much we put attention into something ?
Attention
I think, better if we explain these use sentence :
The animal didn't cross the street because it was too tired
In Natural Language Processing, that sentence would be converted into tokens. These can be whole words, subwords, or character pieces .. depending on the tokenizer. For this example, let's say the sentences are converted into these tokens :
The_ | animal_ | didn_ | '_ | t_ | cross_ | the_ | street_ | because_ | it_ | was_ | too_ | tire | d_
Based on the infamous paper [7], each token gets projected into three vectors, Query (Q), Key (K), Value (V), and the attention score between tokens will be :
Now, we will use some math to find out how much it_ "pays attention" to animal_ compared to street_.
Some Math
To do so, let’s assume this hypothetical vector values that a trained model might output for these words :
- Query for
it_:
- Key for
animal_:
- Key for
street_:
- Key for
was_:
Assume
First, compute the raw score from it_ :
Attending to animal_:
Attending to street_:
Attending to was_:
Then, we apply scaling :
Apply softmax :
So it_ puts roughly 45% of its attention weight on animal_, 35% on was_, and 20% on street_.
The output embedding of it_ becomes a weighted blend of the value vectors, with the strongest contribution coming from animal_.
At the end, it will be something like this :
(Vision) Transformer
Alright, now we know how to "count attention" with words. How those were applied to the image, to be exactly? ...
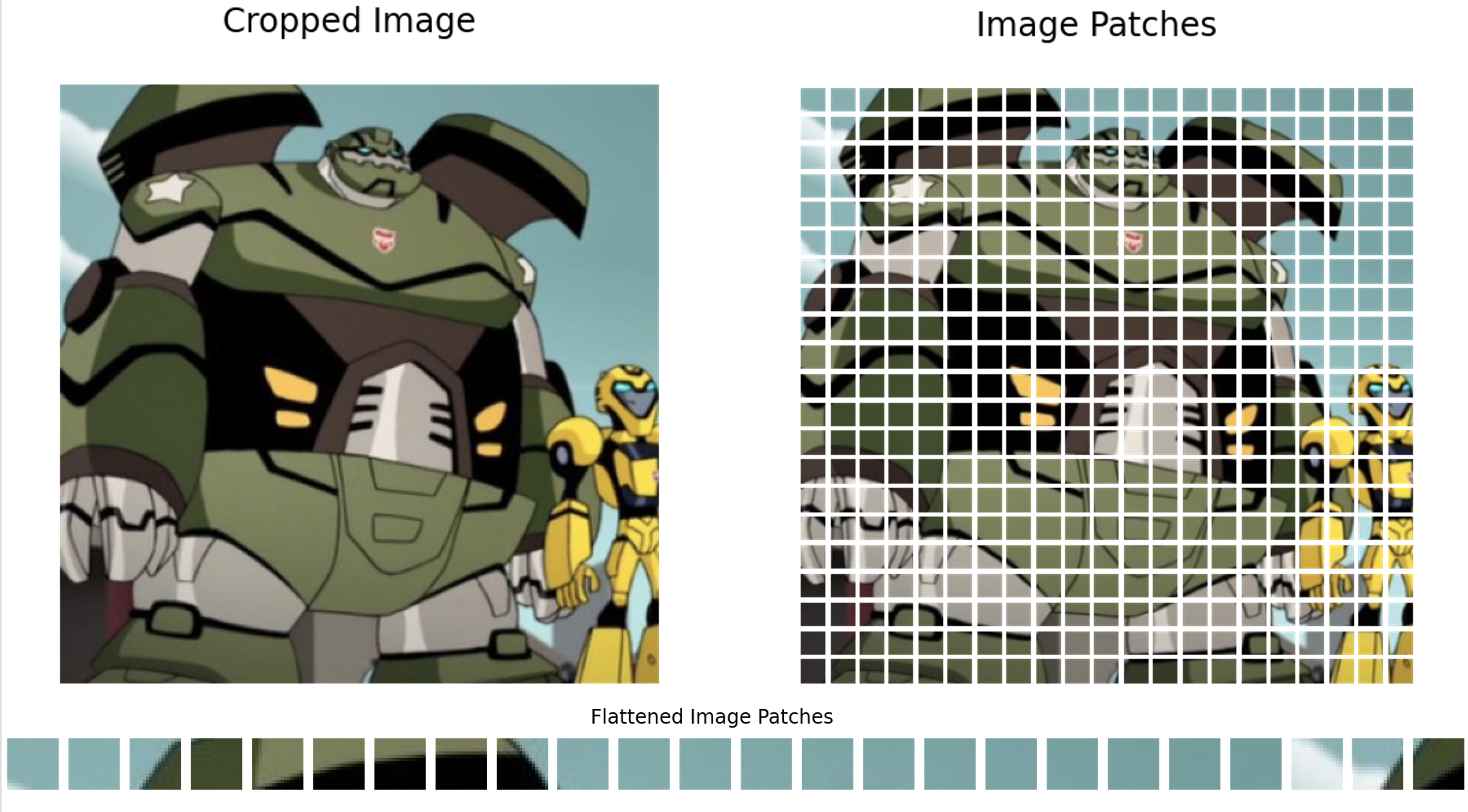
Patch Embedding
Vision Transformer works by cutting the image into patches and treating each patch like a token in a sentence. For example, a 224×224 image with patch size 16×16 :
Each patch is then flattened and mapped into a
Positional Encoding
We have the embedding, now start count attention score ? Not really.
One problem with Transformers is we need to give the order of the input. If you shuffled all the tokens randomly and fed them... well, it still works, but it won't give good information for the model to "understand" the context. The model won't find any difference for an orange image or a scrambled orange puzzle.
With text, it's easy with text because they are ordered, like how we read them from left to right. With images... they don't have natural "reading order" the like words. Patch number 7 isn't inherently "after" patch 6 in any meaningful sense. But a patch containing something like "orange and round" can mean very different things depending on whether it appears in the top-left corner, the center, or the bottom-right. So, to solve this, we add positional embeddings
The final embedding
With :
: A special, extra "classification token" prepended to the sequence (it gathers the final global image info to make a prediction). : This is your image patch ( ) multiplied by a linear projection matrix ( ). This just means we've squashed a patch of pixels into a vector of numbers. : The positional embedding matrix.
The reasoning here .. is basically to make the embedding more grouped by position.
Some Math
Let's take an example. Imagine we are looking at a picture of a landscape. Patch 1 is the top-left corner (blue sky), and Patch 16 is the bottom-right corner (which happens to be a blue lake). Visually, they might look identical.
Let's say our embedding dimension is
- Visual Embedding for Patch 1 (Sky):
- Visual Embedding for Patch 16 (Lake):
If we stopped here, the model would think these two patches are the exact same thing in the exact same context. Now, let's add the positional embeddings (
- Positional Embedding for Position 1 (Top-Left):
- Positional Embedding for Position 16 (Bottom-Right):
Now, we produce the final patch (): - Final Patch 1 Input:
- Final Patch 16 Input:
Ohh? Even though the visual pixels were identical, the final embedding are different, based on the position
Finally, this embedding will be input for Transformer architecture, with it's attention mechanism, MLP head, yadda yadda...
In short, may this diagram helps the intuition :
NH-LoRA
Now, let's see the proposed architecture. Ehhh, wait, I think I still need to explain some terms before that.
Preface
PEFT (Parameter Efficient Tuning)
PEFT, is the "family of techniques" that fine-tune model by updating a small number of parameters. In many cases, these methods can achieve performance that is comparable to fine-tuning all model parameter. So almost same result with less time, win-win solution.
There are really lot of them (well, family technique), I think this figure should give good overview about PEFT [10].
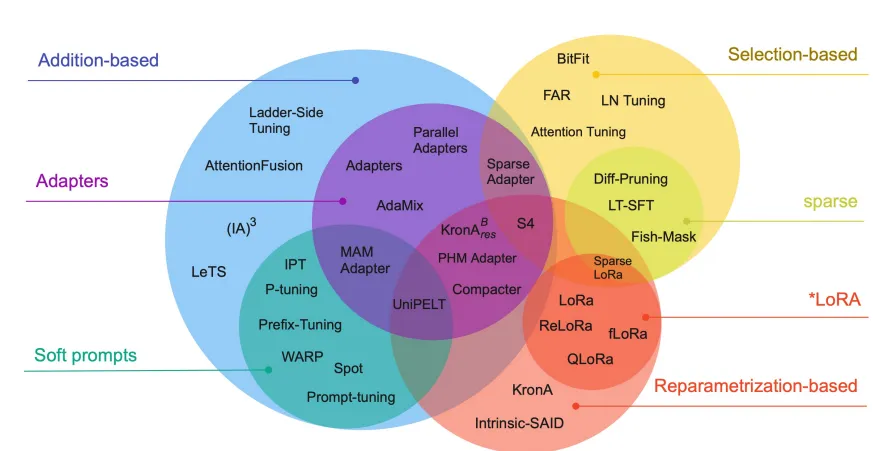
We won't explain all of them (that will be a burden), Let's just focus on LoRA.
LoRA
Okay, so LoRA stands for Low-Rank Adaption, which some technique to approximate updates on weight matrix with a "low-rank decomposition" matrix [11].
... what does that mean? Let's start with diagram for better intuiton :
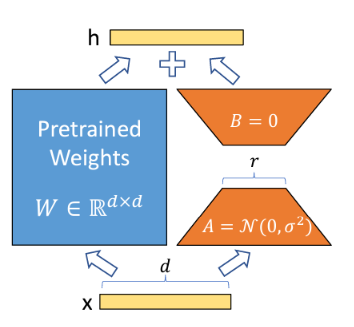
As shown in diagram, we call the original pre-trained weights as
Some Math
Let's take an example. From training, "ideal" weight update
Normally, that's
So, if we multiply
In short, We want to optimize A and B such that
Architecture
Now, let's see the proposed architecture (this time fr).
Btw, some important terms that we'll use a lot here :
-
Adapter: A new module injected into each block of the network to enable parameter-efficient adaptation without modifying the original backbone weights.
-
Block / Layer: The terms block and layer are used interchangeably to refer to a single transformation unit in the model (e.g., a Transformer block).
-
Slot Representation: A slot is a latent vector (embedding) derived from the patch embeddings in a Vision Transformer (ViT), processed through an attention mechanism.
About slot, each slot serves as a compact representation of a learned subspace and is used to generate low-rank factors. Specifically, the slot is used to parameterize the LoRA matrices :
where
These factors are then used to construct the low-rank update :
This mechanism allows each slot to dynamically control the low-rank adaptation applied to the model.
Task-State Encoder
Tasks
Remember when we talk about task in incremental image classification here ? Now.. what is a task, actually?
Task is simply a group or subset of labels. Let's say we have the full set of classes :
Then, these classes are divided into several task groups:
with the condition:
This means that each class belongs to only one task.
Warmup
Suppose task
Warm-up will takes a small initial batch:
Let
be the sample set from the warm-up phase.
With
The feature dispersion is summarized using diagonal covariance or per-dimension variance:
where
To compute a lightweight gradient sketch over trainable parameters during warm-up, we use
where
To compare the current task with previous experience, a similarity signal is computed from the history bank. If
is the summary of previous tasks, then the similarity score is
Here,
We also measures initial uncertainty through the average prediction entropy:
where
All of these statistics are then combined into a raw task vector:
So, to summary this :
Input image pixels and labels
Horizon Planner
Horizon Planner receive two history :
- Current History Task
- Previous History Task from History Bank (if exists)
We know that Current History Task is
Let's say task before current task are as follow :
To make the planner compare the current task not only with a single past task but with the full history, NH-LoRA uses a history aggregation module conditioned on
where
The attention weight for each historical task is computed as
and the aggregated history summary is defined as
For layer
where
Next, the planner maps this input into a latent representation:
where
From the latent representation
where
Decision
Through the value of novelty and conflict, the planner selects one of four actions :
Here,
Let's explain these terms :
Expand rank existing slot
The planner chooses the old slot that is most compatible with the current task. Let
where
The rank of the selected slot is then updated as
with
Open New Slot
To keep parameter growth under control, each layer
If the planner chooses open_new_slot but the slot budget is already full, that decision is redirected to
expand_rank_existing_slot. In that case, the planner reuses the previously defined target slot
If a new slot is allowed, it is initialized with :
Reused Shared
Is to reused share core LoRA and update the shared LoRA based on rank budget, which
mostly low. So the final weight will be something like :
With shared LoRA components at layer
Here:
and are the low-rank projection matrices. is the maximum rank capacity. and are the input and output dimensions of the layer. is a binary mask indicating which rank components are active.
Strong Retention
Is only to reused share core LoRA, like reused share, but without any updated rank on
Instance Router
During the forward pass, the router does not activate all slots at the same time in the task
where
Based on this query, the active slot set is defined as :
with
This means that only the top-
The routing coefficient is then computed only over the selected slots using a TopK-Softmax :
where
At the end, the effective weight used by the block for task
Incremental Cosine Head
In continual learning, classes arrive step by step, so the classifier head cannot stay fixed. After task
This means the classifier head must grow incrementally as new classes appear. A usual linear classifier computes logits as
where
This formulation can be unstable because feature norms may shift across tasks, new classes may dominate old ones, and the bias term can strengthen the imbalance between recent and old classes. As a result, the classifier often becomes biased toward new tasks and suffers from forgetting at the head level.
To address this problem, NH-LoRA uses a cosine classifier, adapted from unified classifier [4]. Instead of relying on feature magnitude, it compares the direction of the feature and class weight vectors:
where
When a new task arrives, the head is expanded by appending new class weights:
For an input
In this way, the head grows incrementally while the scoring rule stays consistent across tasks.
This makes the decision depends on angular similarity instead of vector norm. This is also useful when the backbone representation is modified by adapters such as LoRA, because those updates may change feature scale across tasks.
Consolidation and Homeostasis Unit
After a task is completed, NH-LoRA performs consolidation. For each slot, the model computes its utility
The decision to merge, prune, or keep/freeze the slot is based on usage, stability, redundancy, and the consolidation flag.
The usage of slot
The stability of a slot is defined from the magnitude of its parameter change during task
The redundancy of a slot with respect to other slots in the same block is computed as
Based on these three quantities, the post-task decision is defined as:
and if neither condition is satisfied, then the slot is kept or frozen:
Loss Function
The loss function consists of seven terms. The first four are adapted from the CL-LoRA training objective [2], and the last three are additional regularizers designed from related LoRA adaptation [9,10].
The training objective in NH-LoRA is defined as a weighted combination of classification loss, distillation loss, feature retention loss, subspace regularization, rank regularization, structural growth penalty, and routing regularization:
For the first task, only a subset of these losses is active:
While
As usual, we'll explain these term :
Classification Loss
The classification loss is defined as the cross-entropy between the target label
This loss is applied for the model to correctly predict the labels of the current task.
Logit Distillation Loss
To preserve knowledge about previously learned classes, NH-LoRA uses a teacher model given by the snapshot after task
This loss is applied to current-task samples using a Learning without Forgetting (LwF)-style retention scheme [12].
Feature Retention Loss
In addition to preserving logits, the model is encouraged to keep intermediate representations stable at selected layers:
Here,
Orthogonality Loss Across Slots
To prevent new slots from learning subspaces that are too similar to existing ones, NH-LoRA applies an orthogonality regularizer:
This loss encourages diversity among slots within each layer.
Rank Regularization
To promote compact and efficient capacity usage, the active rank of each slot is regularized by:
This loss is applied to encourages the number of active low-rank dimensions to remain small.
Growth Penalty
To avoid uncontrolled structural expansion, opening a new slot is penalized by:
As a result, new slots are created only when they are truly needed by the current task.
Router Balance
To prevent the router from repeatedly selecting the same slot, NH-LoRA uses a routing balance regularizer:
Here,
So, what is the purpose of each of these loss ?
learns the classes in the current task. preserves responses for old classes through distillation from the previous snapshot. keeps internal features from drifting too far after learning new tasks. pushes new slots away from overlapping subspaces. keeps the active rank small and efficient. controls the creation of new slots so expansion happens only when necessary. prevents routing collapse and keeps slot selection balanced.
Training
Overview
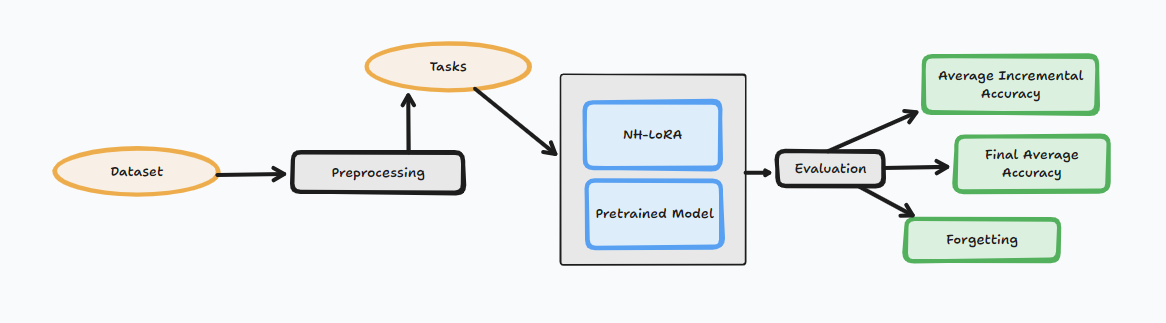
In this class incremental learning setup, the dataset is first preprocessed using PILOT to prepare the samples before they are split into a sequence of tasks. The model then learns each task step by step using a pretrained model with NH-LoRA, which helps it adapt to new classes while reducing catastrophic forgetting on previously learned ones.
After training on each incremental task, the model is evaluated using Average Incremental Accuracy, Final Average Accuracy, and Forgetting. These metrics show not only how well the model learns new classes, but also how much performance it retains on earlier classes throughout the incremental process.
Parameter config
The configuration (batch, learning-rate, etc) can be found here. It contain spesific configuration for each dataset used in this work.
Evaluation
The evaluation for our model consist of two method :
Final Average Accuracy
This metric represents the average accuracy at the very end of training, after the model has learned all tasks. In other words, it measures how well the final model performs across every task or class that has appeared so far. This is the main score used to summarize the overall final performance of the continual learning process.
It is calculated as follows:
where:
is the total number of tasks, is the accuracy on task after training the final task .
Forgetting
Forgetting measures how much performance on earlier tasks drops after the model learns new tasks. In continual learning, this is an important metric because a model may achieve high accuracy on the latest task while gradually losing knowledge from previous tasks. A lower forgetting value means the model preserves past knowledge better.
where:
is the total number of tasks, is the best accuracy ever achieved on task before the final task, is the accuracy on task after training the final task.
A higher value means more forgetting, while a lower value means better retention of previously learned tasks.
We have run 8 experiment (detailed explanation here ), and here are the best result for each dataset :
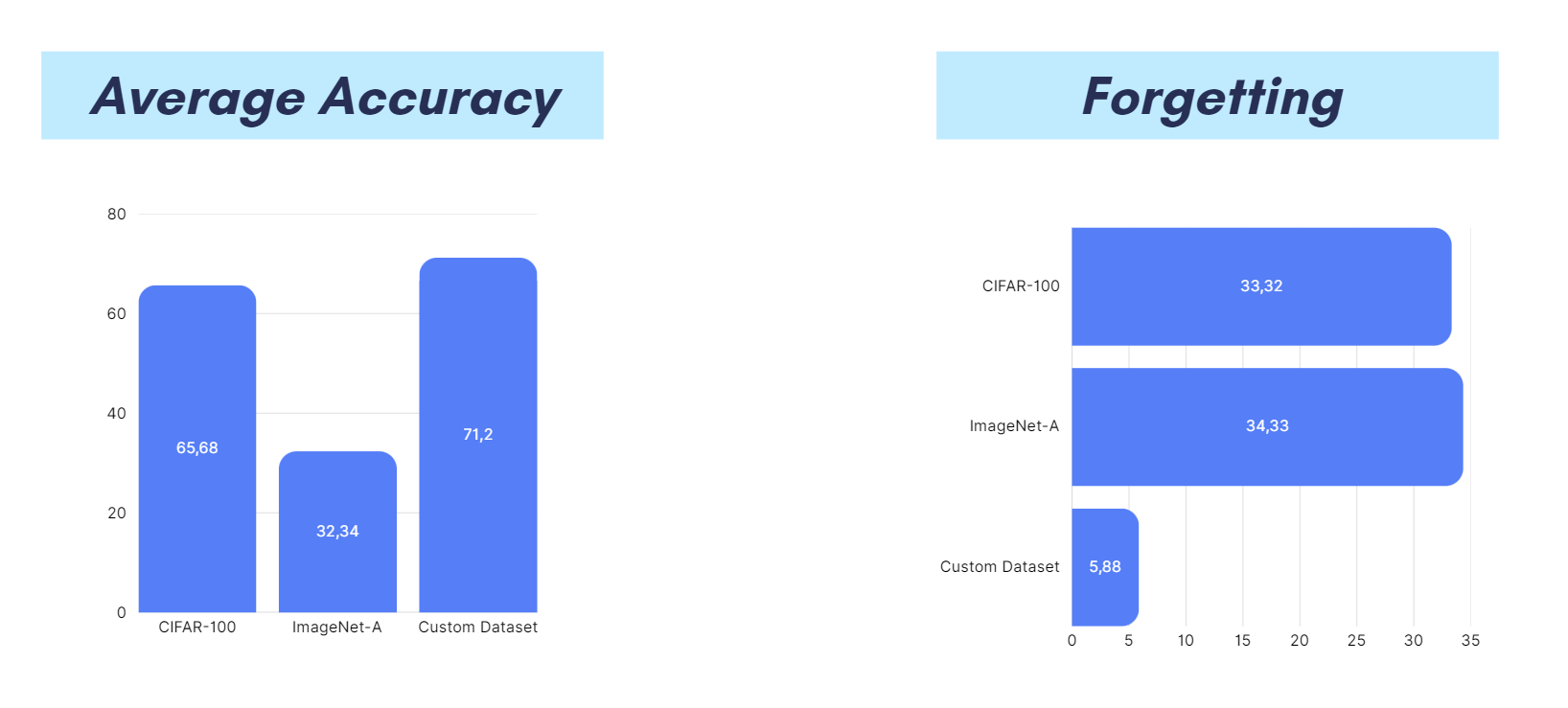
Conclusion
Well, as we can see up there, NH-LoRA does help the model learn new classes without either fully retraining from scratch or modifying all backbone parameters. The proposed adapter design is applied across all layers to preserve plasticity, which differs from methods such as CL-LoRA that rely on more specialized adapters in selected layers [2]. In this sense, the architecture is designed to adapt its structure according to task novelty and conflict, instead of using the same fixed adaptation strategy for every task. Therefore, this should improve flexibility and allow capacity to be allocated more effectively, especially when the incoming task has a different level of similarity to previous ones.
However, we still need to adjust some our expectation for the result. The model still struggles to maintain old knowledge while learning new tasks, so the forgetting issue is still present. It may benefit from the horizontal planner mechanism, yet the extra conditions and regularization also make the optimization harder if they are not well balanced.
We also have to remember that the result is also likely affected by training configuration differences, such as task split, number of epochs, learning rate, and other hyperparameters. This need to examine further, as we don't have more budget for another experiment :( , and every experiment does take time (CIFAR itself need around 5-6 hours per fine-tuning).
Future Works
For future work, NH-LoRA would benefit from more extensive experimentation, especially on parameter tuning and task-setting variations. Since continual learning performance is highly sensitive to hyperparameters, a more systematic search over learning rate, rank budget, regularization strength, and task split could give a clearer picture of the method’s true potential.
References
[1] D.-W. Zhou et al., “Class-Incremental Learning: A Survey.” 2023. [Online]. Available: https://arxiv.org/abs/2302.03648
[2] J. He, Z. Duan, and F. Zhu, “CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning.” 2025. [Online]. Available: https://arxiv.org/abs/2505.24816
[3] V. Lialin et al., “Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning.” 2023. [Online]. Available: https://arxiv.org/abs/2303.15647
[4] B. Jung et al., “Neuromorphic Computing - An Overview.” 2025. [Online]. Available: https://arxiv.org/abs/2510.06721v2
[5] S. Hou et al., “Learning a Unified Classifier Incrementally via Rebalancing.” 2019. [Online]. Available: https://openaccess.thecvf.com/content_CVPR_2019/html/Hou_Learning_a_Unified_Classifier_Incrementally_via_Rebalancing_CVPR_2019_paper.html
[6] J. Yoon et al., “Lifelong Learning with Dynamically Expandable Networks.” 2018. [Online]. Available: https://openreview.net/forum?id=Bk-aoer_-
[7] A. Dosovitskiy et al., “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.” 2020. [Online]. Available: https://arxiv.org/abs/2010.11929
[8] A. Vaswani et al., “Attention Is All You Need.” 2017. [Online]. Available: https://arxiv.org/abs/1706.03762
[9] Z. Hu et al., “Low Rank Regularization: A review.” 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0893608021001468
[10] A. Rokah et al., “Mixture-of-Experts Models in Vision: Routing, Optimization, and Generalization.” 2026. [Online]. Available: https://arxiv.org/abs/2601.15021v1
[11] E. J. Hu et al., “LoRA: Low-Rank Adaptation of Large Language Models.” 2021. [Online]. Available: https://arxiv.org/abs/2106.09685
[12] Z. Li and D. Hoiem, “Learning without Forgetting.” 2016. [Online]. Available: https://arxiv.org/abs/1606.09282